В прошлой части мы остановились на настройке аутентификации. Перейдем к следующему заданию
Настройка STUB и NSSA областей:
- На R11 создайте статические NULL-маршруты для следующих сетей: 0.0.0.0/0, 20.20.0.0/24, 20.20.1.0/24, 20.20.2.0/24
Статические маршруты настраиваются в контекста routing-options:
Проверим результаты настройки:
Маршруты появились в таблице маршрутизации. Идем дальше:
- Между R11 и R10 настройте RIP таким образом, чтобы устанавливались связности только по RIPv2-протоколу
R10 и R11 между собой подключены через интерфейс ge-0/0/3.1011. Для того, соседства были только RIPv2, нужно также указать, чтобы роутеры получали только RIPv2-пакеты, а отправляли только multicast-пакеты:
Проверим соседей и маршруты по протоколу RIP:
R10:
R11:
В обоих случаях видно, что у нас действительно настроен RIPv2 (поля send и receive), но в таблице маршрутизации пока нет маршрутов, поэтому однозначно утверждать о правильности конфигурации мы пока не можем. Перейдем к следующей части задания:
- С R11 проанонсируйте в сторону R10 loopback-интерфейс, а также статические маршруты
Чтобы проанонсировать direct и static-сети нужно создать специальную политику и применить ее в контексте настройки протокола rip. Начнем с политики, нам нужно с R11 проанонсировать адрес 192.168.100.11/32 и статические маршруты. Сделаем настройку для каждого пункта отдельно, назвав общую политику rip_export:
Итого, политика получилась такая:
Здесь мы указали, что из direct-сетей необходимо пропустить только сеть 192.168.100.11/32. Теперь создадим правило для статических маршрутов:
Итоговая конфигурация политики:
И теперь применим эту политику в качестве правила экспорта в контексте rip:
Итоговая конфигурация rip для R11:
Сохраняем конфигурацию и проверим таблицу маршрутизации на R10:
Отлично, маршруты от R11 прилетели. Теперь действительно ясно, что RIP-соседство установлено. Идем дальше:
- C R10 отдайте в сторону R11 direct-сети, а также сети, получаемые по OSPF
Общий вид политики:
И теперь применим ее к протоколу rip:
Проверим таблицу маршрутизации R11:
И снова все прекрасно, маршруты прилетели.
- На R10 маршруты, полученные по RIP, проанонсируйте в OSPF-процесс (кроме маршрута 0.0.0.0/0)
Общий вид политики таков:
Поскольку в задании сказано, что экспортировать дефолтный маршрут не нужно, сначала нужно создать условие deny-default которое бы отбрасывало этот маршрут, а уже после этого вторым правилом брать все маршруты, полученные по RIP, и пропускать в OSPF
Применяем политику:
Проверим новые маршруты на R5, дабы убедиться, что импортированные из RIP сети распространились по OSPF:
А если R8?
Отлично, как Loopback-адрес, так и статические маршруты успешно распространились по OSPF-сети.
- Настройте область 40 как STUB-area, проследите за изменениями в базе данных OSPF (LSDB) и таблице маршрутизации
Для начала проверим LSDB и таблицу маршрутизации:
На R10 LSDB смотреть нет смысла, поскольку она будет полностью идентична R6. Больший интерес представляет R3:
Поскольку R3 принадлежит нулевой области, он хранит в себе базы данных состояния каналов со всех областей. R6 же хранит в себе только информацию о своей области, а также информацию об экспортированных из других протоколов маршрутизации, поскольку R6 является ASBR.
Настроим область 40 как STUB:
R3:
R6:
R10:
Убедимся в установлении соседства:
Теперь проверим таблицу маршрутизации и LSDB R6:
R3:
Поскольку основная цель STUB-area — сократить размер LSDB, в ней не могу распространяться LSA4 и LSA5, следовательно, маршрут из RIP не был экспортирован в OSPF. Это наглядно показывает LSDB и таблица маршрутизации.
- Настройте area 40 как totally-stub area. В качестве дефолтной метрики выставите значение 80. Что на этот раз произошло с LSDB и routing table?
Totally-stub area настраивается на ABR, при этом запрещается анонсирование LSA3 внутрь тупиковой области:
Проверим таблицу маршрутизации и LSDB на R6:
LSDB сократилась до минимальных размеров, она содержит в себе только маршруты, созданные в area 40, а также дефолтный маршрут, полученный от R3 с измененной метрикой. Аналогично с таблицей маршрутизации. На R3-же все осталось без изменений:
- Измените тип area 40 на NSSA, какие изменения в таблице маршрутизации и LSDB произошли?
Как видно, в R3 и R10 была введена команда, а в R6 — нет. Но при этом stub была заменена на nssa:
Это происходит автоматически, поскольку область может быть либо stub, либо nssa. Проверим изменения в LSDB и таблице маршрутизации на R3 и R6:
R3:
На R3 видно, что помимо префиксов, принадлежащих area 40, в нулевую область прилетели внешние маршруты, полученные по протоколу RIP. В OSPF они отмечены как External и принимаются с AD (Administrative Distance или preference) = 150 (, в отличии от обычных OSPF-маршрутов, у которых AD = 10.
R6:
В таблице маршрутизации R6 присутствуют все OSPF-сети, плюс внешние маршруты. Состояние LSDB для area 40 соответствует LSDB на R3.
- Теперь установите area 40 как totally nssa. На узле R10 дефолтный маршрут, полученный по протоколу RIP, используйте в качестве основного маршрута по-умолчанию.
Totally nssa, как и stub nssa настраивается на ABR:
Значение метрики указываем произвольное, возьмем 80. И в итоге получилась такая конфигурация:
Проверим таблицу маршрутизации R6:
Перейдем к R10:
Здесь видно, что у маршрута 0.0.0.0/0 есть 2 источника — RIP и OSPF. Причем приоритетным является OSPF, поскольку его AD = 10. У RIP же AD = 100. Нужно либо увеличить AD OSPF, либо уменьшить AD RIP. Пойдем по второму пути. Установим preference = 9. Для этого напишем политику:
И применим ее к нашему RIP-соседу:
Таблица маршрутизации R10 для дефолтного маршрута:
Отлично, сейчас приоритетным стал RIP-маршрут и весь трафик по-умолчанию будет ходить через него.
На R6 же правки конфигурации R10 никак не повлияли:
Перейдем к следующей части задания
Настройка суммарных маршрутов:
- Для сетей 20.20.0.0/24, 20.20.1.0/24 и 20.20.2.0/24, получаемых от R11 по протоколу RIP настройте суммарный маршрут и отдайте его в магистральную область
Данная конфигурация также настраивается на ABR в режиме настройки nssa area 40 (в нашем случае). В общем виде команда выполняется так:
где <AREA-RANGE> — суммарный маршрут. В нашем случае лучше всего подойдет сеть 20.20.0.0/22, которая будет включать в себя сети от 20.20.0.0/24 до 20.20.3.0/24. Пропишем на оборудовании настройки:
Проверим таблицу маршрутизации R3:
Здесь у нас, помимо суммарного маршрута, присутствуют оригинальные сетки. Это связано с тем, что R3 подключен к area 40, где эти маршруты и были импортированы в OSPF. Также стоить обратить внимание, что preference суммарного маршрута будет равен максимальному preference составных сеток. То есть, если бы у нас одна из сетей имела preference 170, то и суммарный маршрут был бы со значением 170.
Проверим таблицу маршрутизации R1:
Отлично, прилетел всего один суммарный маршрут.
- Попробуйте вышеуказанное объединение сетей, но уже с опцией RESTRICT. Создайте ситуацию, которая продемонстрировала бы функционал этой опции
Если суммарный маршрут создается с опцией RESTRICT, то это означает, что все сети, входящие в общую сеть, перестанут анонсироваться за пределы своей области. Для начала на R3 добавим опцию RESTRICT:
Проверим таблицу маршрутизации R1:
И действительно, как мелкие маршруты (20.20.0.0/24, 20.20.1.0/24, 20.20.2.0/24), так и общий (20.20.0.0/22) пропали из таблицы маршрутизации. Давайте теперь на R3 в качестве суммарного маршрута возьмем префикс 20.20.0.0/23:
Теперь, судя по логике, за пределы area 40 должна выйти лишь подсеть 20.20.2.0/24, поскольку в сеть 20.20.0.0/23 входят только 20.20.0.0/24 и 20.20.1.0/24:
И действительно, за пределы area 40 вышла лишь одна сеть, которую мы и ожидали.
Перейдем к следующей части задания
Настройка multi-area
- Разорвите OSPF-соседство между R1 и R4 и выполните трассировку с R1 до R4. Оптимален ли данный маршрут?
- Настройте multi-area соседство между R1 и R2 для ospf area 10
- Повторите процедуру трассировки и убедитесь в корректности настройки
Перед тем как разорвем соседство, выполним просто трассировку от R1 к R4 (между loopback-адресами):
То есть между R1 и R4 есть прямая связность, что и доказала трассировка. Деактивируем OSPF на интерфейсе ge-0/0/5.14 R1:
Проверим состояние соседства:
Отлично, связность пропала. Снова выполним трассировку от R1 до R4:
root@VR-Device-1> traceroute 192.168.100.4 source 192.168.100.1 routing-instance R1
traceroute to 192.168.100.4 (192.168.100.4) from 192.168.100.1, 30 hops max, 40 byte packets
1 172.20.15.2 (172.20.15.2) 1.485 ms 1.266 ms 1.375 ms
2 172.20.25.1 (172.20.25.1) 1.712 ms 1.751 ms 1.813 ms
3 192.168.100.4 (192.168.100.4) 2.703 ms 3.095 ms 3.974 ms
Получается, трафик идет по такому маршруту: R1 — R5 — R2 — R4, что не есть самый оптимальный маршрут
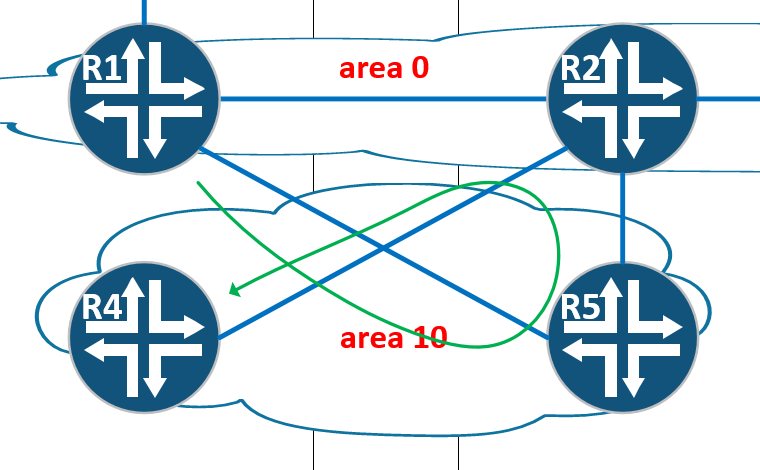
Правильнее было бы пустить трафик по маршруту R1 — R2 — R4. Для этого необходимо выполнить замыкание OSPF area 10 между R1 и R2. Делается это следующей командой:
где <AREA-ID> — номер OSPF-области, для которой нужно выполнить замыкание,
<INTERFACE-NAME> — интерфейс, через который нужно выполнить замыкание
В нашем случае нужно замкнуть area 10 между интерфейсами ge-0/0/3.12 маршрутизаторов R1 и R2.
Конфигурация для R1:
Конфигурация R2:
Проверим OSPF-соседей на R1:
Выше видно, что через интерфейс ge-0/0/3.12 у нас установлено 2 ospf-соседства: для area 0 и area 10. Заглянем чуть глубже в ospf-интерфейс ge-0/0/3.12:
Более подробный вывод показывает, что для area 10 у нас тип соединения точка-точка (p2p), а также видно, что интерфейс secondary, то есть используется для настройки multi-area.
Глянем аналогичное на R2:
Как видно, информация аналогична той, что была на R1. Выполним теперь трассировку от R1 до R4:
Теперь видно, что трафик пошел правильным маршрутом: R1 — R2 — R4.
Настройка virtual-link
- Разорвите OSPF-соседство между R1 и R9. Доступна ли area 30 из других сетей?
- Восстановите разорванное соседство и настройте virtual-link для area 20 и area 30
- Проверьте работоспособность сети в случае обрыва
Отключаем OSPF между R1 и R9, деактивируя интерфейс ge-0/0/5.19 на R1:
Проверим маршрут до Loopback-адреса R1 на R1, R2 и R3:
Как видно выше, ни на одном из магистральных роутеров маршрут до сети 192.168.100.9/32 не был обнаружен, даже несмотря на то, что R3 находится в ospf area 20, которая соседствует с area 30, хотя в LSDB R3 эта сеть присутствует в area 20:
Но вот в таблице маршрутизации R7 данный маршрут присутствует и даже отвечает на icmp-запросы
Это связано с тем, что только ABR может импортировать маршруты из одной ospf-области в другую. А для area 30 ABR является R1 и R9. Но для полноценной работы R9 в качестве ABR необходимо соединить R9 с магистральной (нулевой) областью. Делается это при помощи virtual-link. Общий синтаксис таков:
где <TRANSIT-AREA-ID> — номер области, через которую будет проходить virtual-link
<NEIGHBOR-ID> — IP-адрес роутера ABR, до которого мы будем строить virtual-link
Вернем OSPF-соседство между R1 и R9:
Теперь построим virtual-link между R1 и R8.
Проверим OSPF-соседства на R8:
Как видим, у нас появилось еще одно установившееся соседство с адресом 172.20.19.1 и ID 192.168.100.1. Причем соседство установлено через интерфейс vl-192.168.100.1 (где vl — virtual-link, а IP — адрес соседа, с кем установлена связность). Глянем более детально информацию об этом интерфейсе:
Тип интерфейса virtual говорит нам о том, что это virtual-link, и также у нас установлена p2p-связность. Area 0, как раз то, чего мы и добивались.
Проверим OSPF соседей на R1:
Абсолютно аналогичные показатели, новое соседство в area 0 через интерфейс vl-192.168.100.8.
Настроим связность между R8 и R3:
Проверим соседей на R8:
Отлично, новое соседство установилось. Теперь давайте снова разорвем связность между R1 и R9:
И проверим на R1 наличие маршрута к R9:
Маршрут есть и прилетает от R2. Проверим R3:
И здесь все прекрасно. Маршрут прилетел от R7. Как видим, резерв работает.
Вернем связность R1-R9 и отключим R3-R7:
Убедимся, что на R3 маршрут к 192.168.100.7 (R7) прилетает напрямую от R7:
Отлично, так и есть. Отключаем на R3 интерфейс ge-0/0/5.37 (между R3 и R7)
Снова проверим маршрут:
Как и ожидалось, получаем его от R2. Выполним трассировку:
Из результатов видно, что маршрут к R7 такой: R3 — R2 — R1 — R9 — R8 — R7. Чего мы, собственно, и добивались.
Перейдем к заключительной части лабы:
Управление метриками
- На всех узлах стройте reference-bandwidth на значение 10g
- В area 10 сделайте так, чтобы трафик от R4 шел через узел R2, а трафик с R5 — через R1
- Настройте метрики virtual-link таким образом, чтобы трафик через него шел только в случае обрыва основного линка до AREA 0
- На R2 настройте OSPF с функцией OVERLOAD. Проследите изменения в таблице маршрутизации
Перед настройкой reference-bandwidth глянем таблицы маршрутизации R1 и R2, а конкретно маршруты до loopback-адресов этих роутеров:
В обоих случаях маршруты имеют параметр metric = 1. Этот параметр как раз и высчитывает на основе reference-bandwidth, который высчитывается по формуле metric (или cost) = reference-bandwidth / interface-bandwidth. По-умолчанию, в ospf reference-bandwitdh равен значению 1G (или 1 000 000 000 b). А поскольку мы используем гигабитные интерфейсы, то на всех портах метрика будет равна единице. В нашем случае это может быть и достаточно, но reference-bandwidth рекомендуется выставлять равному максимальной пропускной способности интерфейса * 10. Мало ли, сеть в дальнейшем будет расширяться, будут собираться LAG, вставляться новые платы с более скоростными портами. Выставим reference-bandwidth = 10G на R1 и R2. Делается это в контексте настройки ospf:
Снова проверим маршруты между R1 и R2:
Теперь значение метрики = 10, поскольку метрика посчиталась по вышеупомянутой формуле (10G / 1G = 10). Выполним аналогичные настройки на всех OSPF-роутерах:
Убедимся, что изменения применились:
Отлично, в таблицах маршрутизации нет метрик меньше 10, что означает корректность конфигурации. Все метрики автоматически были посчитаны и занесены в таблицу маршрутизации.
Помимо автоматического подсчета метрик их можно выставить принудительно на отдельном интерфейсе. Делается это в режиме конфигурации ospf-интерфейса. Перейдем к следующей части задания:
- В area 10 сделайте так, чтобы трафик от R4 шел через узел R2, а трафик с R5 — через R1
Поскольку у нас теперь дефолтная метрика равна 10, между узлами R1-R4 и R2-R5 метрику нужно сделать еще больше. Фактически, между R1 и R4 стоимость маршрута должна быть больше 20, поскольку альтернативный маршрут от R4 к R1 будет идти по маршруту R4-R2-R1, где суммарная метрика будет равна 20 (сумма метрик между роутерами). Следовательно, чтобы трафик к R1 шел через R2, надо метрику сделать выше 20. Возьмем 30:
Маршрут до R1 с R4 теперь выглядит так:
И, соответственно, трассировка:
Выполним аналогичные действия между R2 и R5:
Проверим трейсы и маршрут с R5:
Готово. Аналогично можно сконфигурировать метрики через virtual-link. Настроим metric = 50 для созданных нами virtual-link:
Проверим маршрут до R1 с R8:
Маршрути прилетел от R7 с метрикой 31.
Теперь настроим на R2 ospf overload:
Проверим таблицу маршрутизации R1, R2 и R3:
После настройки OVERLOAD на R2 все префиксы в таблице маршрутизации R2 стали иметь значение metric = 65536, а маршруты на R1 и R3 стали вместо использования узла R2 в качестве транзитного использовать узлы R9 и R7, соответственно. Функция overload нужна для того, чтобы увести весь транзитный трафик с роутера с целью проведения каких-либо работ, которые могли бы повлиять на прохождение трафика через него.
Выполним трассировку от R6 до R5:
Поскольку на R2 все метрики оказались завышены, весь трафик теперь ходит, минуя R2. Но сам R2 по-прежнему остается доступен по кратчайшему пути:
На этом лабораторная работа окончена. Если остались какие-то вопросы или пожелания, пишите в комментарии. Обязательно отвечу и приму во внимание
One thought on “Juniper. Лабораторная работа по OSPF уровня professional. Пошаговое решение. Часть 2.”